
Data pipeline failures: How does it impact your business?


Table of Contents

TL; DR
- Data pipeline failure is one of the most expensive and underestimated risks in modern data organizations
- Most pipeline failures are predictable, not random, and repeat across companies and industries
- Schema drift, bad data, and brittle orchestration break pipelines more often than infrastructure outages
- Pipeline failures damage trust, slow decisions, and quietly erode revenue and forecasting accuracy
- Manual fixes and fragmented tools increase failure points instead of reducing them
- Reliable data requires automation, governance, monitoring, and consistency across the entire pipeline
Every executive knows data drives decisions, but what happens when the data pipeline fails? A single data pipeline failure can cascade into missed opportunities, delayed reports, and misguided strategies.
Beyond dollars, data pipeline failures impact trust. If your finance and sales teams constantly argue over whose numbers are “right,” or if managers resort to manual Excel workarounds, confidence in data collapses. When that happens, every report or dashboard becomes suspect.
In a world where agility and data-driven strategy are everything, a single data pipeline failure can halt your business momentum. It’s a board-level risk. That’s why forward-looking companies invest in resilient, observable data pipelines. In the next sections, we’ll unpack common data pipeline failures, their root causes, and how to detect data pipeline issues before they wreak havoc on your business.
6 Common data pipeline failures
Even the best teams encounter pipeline problems. Data pipelines involve many moving parts—extraction, ingestion, transformation, storage, BI—and a failure in any can break the whole chain.
Here are the most common data pipeline failures that organizations face, and how they undermine your data initiatives:
1. Schema drift and breaking changes
Your data sources won’t stay static. Upstream systems get upgraded, columns are added or renamed, API responses change format. This schema drift can silently break downstream workflows.
For instance, if a marketing API adds a new field, it might throw off your ETL mappings or cause type errors in your transformation code.
Schema-related data pipeline failures ripple across dashboards and models; suddenly reports have missing metrics or jobs start failing. These failures often go undetected until a user spots something “off,” delaying critical insights.
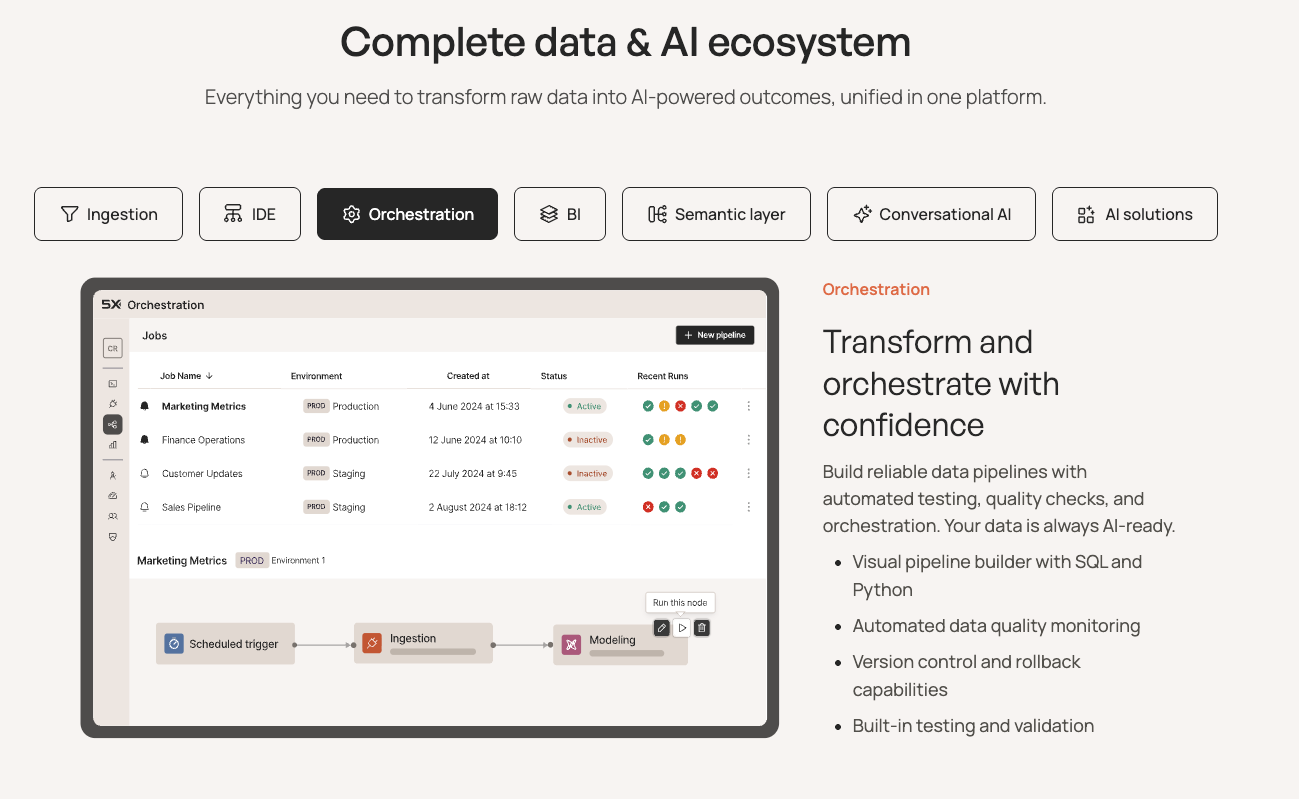
5X addresses schema drift by combining modular, version-controlled pipelines with automated validation. Its ingestion layer includes 600+ real-time connectors that can detect changes at the source and alert your team. The result is a resilient pipeline that evolves with your data without constant firefighting.
2. Data quality error
Not all pipeline failures are technical crashes. Some are worse: the pipeline runs but delivers bad data. Poor data quality forces teams to spend most of their time troubleshooting data quality issues instead of generating insights. As a result, businesses in the US alone lose $3 trillion annually to poor data.
These issues can arise from anything like a dirty source file, an unhandled null in a transformation, a join that multiplies records.
Also read: Data Reliability Guide: How To Build Trust In Your Data Pipelines
3. Pipeline orchestration failures
Modern pipelines rely on orchestration tools (Airflow, Dagster, dbt Cloud, etc.) to schedule and manage complex workflows. Orchestration failures, like a task error, a dependency not met, a runtime timeout, are a common cause of incomplete data. Perhaps a nightly ETL job fails halfway, leaving downstream tables empty, or a scheduling conflict prevents a critical job from running on time.
4. Broken data integrations and connectors
Many pipelines break because an API changed an endpoint, a credential expired, or a source system went down.
For example, if your pipeline pulls data from a SaaS CRM and that API introduces new rate limits or fields, your integration might start erroring out. Suddenly no new data is flowing in. Connectors failing can be catastrophic since they are the pipeline’s lifeline to raw data.
5. Faulty transformations and logic errors
Even when data is flowing and jobs are scheduled, pipelines can fail due to errors in transformation logic or coding mistakes. A misconfigured join, a division by zero, or a script that runs on one dataset but fails on another can all cause pipeline runs to stop.
These are classic “pipeline broke last night” scenarios that data engineers dread. They often happen when a new update is rolled out (e.g., a new metric or model added to the pipeline). Poor development practices (lack of testing or code review) make this more likely.
6. Lack of end-to-end visibility
A subtler but critical failure mode is when pipelines break and nobody notices until too late because of insufficient monitoring. Many organizations lack end-to-end observability. If data gets stuck or delayed at one stage, downstream processes quietly use stale data.
Without a unified view (data lineage, health metrics, alerts), small errors compound into big ones
With 5X, you get dashboards tracking pipeline run times, data freshness, row counts, and anomalies in one place. You can see, for example, that yesterday’s load for table X was 20% lower than usual or that a particular DAG hasn’t run successfully in two days.
How to prevent your data pipelines from breaking
Preventing data pipeline failures comes down to foresight and good engineering hygiene. You want to catch issues before they impact the business (or better yet, design them out entirely).
Here are key strategies to prevent pipeline breakage and keep your data flowing smoothly:
1. Implement end-to-end observability and alerts
You can’t fix what you can’t see. Establish monitoring for every pipeline stage—ingestion, processing, and delivery. Set up automated alerts for anomalies in data volume, freshness, or schema.
For example, if a daily record count suddenly drops by 50% or a job runs 2 hours longer than usual, your team should know immediately.
Adopting a data observability tool or platform (like the one built into 5X) helps detect data pipeline issues early, often before business users are affected.
2. Automate and test everything
Manual processes are the enemy of reliability. Wherever possible, use automation in your data pipelines: automated data ingestion (with managed connectors), automated data validation, and automated deployments. This reduces human error and ensures consistency.
For example, instead of manually exporting CSVs and uploading them (high risk of mistakes), use a tool or service that automatically pulls data from sources on schedule.
Similarly, implement automated data quality tests. E.g., if yesterday’s sales data has >5% null values, fail the pipeline and alert an engineer.
Treat your pipeline like software: use a CI/CD pipeline for your data transformations so that any code change triggers tests (on a subset of data) before it goes live. Automation also extends to maintenance: use infrastructure-as-code for your pipeline setup so that environments are reproducible.
Also read: Data integration automation: How to eliminate manual ETL and speed up insights
3. Design for resiliency and decoupling
A resilient pipeline is one that handles failures gracefully. Build in retries, backoff strategies, and idempotent operations (so rerunning a job won’t corrupt data). Decouple pipeline stages where possible; for instance, use a message queue or staging area between ingestion and processing, so a failure in one area doesn’t halt everything.
Make use of checkpointing. if a large job processes 1M records, commit progress every 100k so you don’t redo from scratch on failure. Also consider parallelism and load balancing: a spike in data volume shouldn’t crash your pipeline; it should scale out. Cloud-based data architectures (e.g., autoscaling compute in Snowflake or EMR) can help handle variable loads without failing.
As an example, some organizations adopt a “circuit breaker” pattern. If a downstream system is slow, the pipeline can temporarily skip sending data there rather than failing entirely.
Using modern orchestration (like Kubernetes-based scheduling or tools like Dagster) allows setting these dependencies and fallbacks. In practice, 5X embraces this with open-source frameworks and an open architecture: you’re not locked into one monolithic system, so you can always swap components or extend the pipeline without breaking others.

4. Enforce data governance and schema management
Establish schema contracts for your data. If upstream teams plan a change, they must notify or coordinate with data engineering.
Use a semantic layer or data catalog to manage definitions of key metrics and fields, so that everyone (from source owners to analysts) speaks the same data language. This prevents the “accidental” failures where someone changes a data type or units and downstream calculations implode.
It’s also important to maintain thorough documentation of your pipeline and data assets. When something does go wrong, having lineage information (what feeds into this table, who uses it, what does it mean) accelerates root cause analysis.
5. Invest in expertise and training
People are a huge factor. Many pipeline failures ultimately trace back to human error; a junior engineer unfamiliar with a legacy script, or an analyst who unknowingly deletes a crucial column. Mitigate this by training your team in data engineering best practices and cultivating a culture of quality. Have code reviews for pipeline changes. Pair newcomers with experienced data engineers for critical projects.
A redditor expressed their frustration on how data pipelines fail due to companies trying shortcuts:
Also, don’t overload one person with owning the entire pipeline end-to-end without support. Instead, consider managed services or fractional experts to set up the foundation correctly.
This is where 5X may be of value. We bring in a team’s worth of best practices embedded in the product. And if you do have data engineers in-house, freeing them from maintenance toil means they can work on preventive improvements (like better tests, new quality checks, performance tuning) that further reduce failures.
6. Continuously review and improve your pipelines
Schedule regular pipeline health checks and post-mortems for any incident. Analyze trends: Are certain failures happening repeatedly? Is a particular data source flaky every quarter end?
Use those insights to harden the pipeline. Maybe that flaky source needs a more frequent pull to catch up on missed data, or that heavy transformation could be refactored for efficiency.
Many teams adopt a “data reliability scorecard”, tracking things like pipeline success rate, data freshness SLA compliance, and incident frequency. This turns reliability into a measurable KPI that leadership cares about.

Aim to gradually raise the bar. For instance, you may want to reduce average incident resolution time from 15 hours to under 5 hours, or cut the number of times stakeholders find issues first.
If you use 5X, a lot of this continuous improvement is facilitated by the platform itself: you get update notifications, and performance metrics. It’s a dynamic environment that keeps evolving with your needs, ensuring your pipelines get more resilient every day.
How 5X helps eliminate pipeline failures
Data pipeline failures are business problems. As we’ve seen, they can stall your analytics, hurt customer trust, and cost millions in inefficiencies.
The good news is that with the right strategies and tools, you can detect and prevent data pipeline issues before they impact the business. It requires a proactive approach: automating your pipelines, monitoring them diligently, engineering them for resilience, and instilling DataOps discipline in your team.
It might sound like a lot, but you don’t have to do it alone.
5X is an all-in-one data platform that was built from the ground up to deliver reliable, production-grade pipelines without the usual firefighting. With 5X, you get automated ingestion, a secure data lake/warehouse, built-in transformations, and even AI-powered BI unified in one platform.
FAQs
How do data pipeline failures affect revenue forecasting and financial planning?
Can modern cloud data stacks still experience pipeline failures?
How do data pipeline failures affect AI and machine learning initiatives?
When should companies move away from DIY data pipelines?
Building a data platform doesn’t have to be hectic. Spending over four months and 20% dev time just to set up your data platform is ridiculous. Make 5X your data partner with faster setups, lower upfront costs, and 0% dev time. Let your data engineering team focus on actioning insights, not building infrastructure ;)
Book a free consultationHere are some next steps you can take:
- Want to see it in action? Request a free demo.
- Want more guidance on using Preset via 5X? Explore our Help Docs.
- Ready to consolidate your data pipeline? Chat with us now.
Related articles


.png)

How retail leaders unlock hidden profits and 10% margins
Retailers are sitting on untapped profit opportunities—through pricing, inventory, and procurement. Find out how to uncover these hidden gains in our free webinar.
Save your spot










