
Data Reliability Guide: How To Build Trust In Your Data Pipelines And Eliminate Costly Errors

.png)

Table of Contents

TL; DR
- Data reliability protects you from making big decisions based on the wrong data
- Data reliability means your data stays accurate, consistent, complete, and timely
- Reliable data turns dashboards into trusted decision-making tools
- Most data breaks because of human errors, schema changes, bad integrations, silos, and lack of a proper monitoring mechanism
- AI automates validation, cleaning, lineage, and real-time anomaly detection
- Data observability tools help teams catch issues proactively
- Organizations must build a system where data is consistently trustworthy, teams make decisions with confidence, and bad data never blindsides you again
For founders and top executives, the only thing worse than having no data is making expensive business decisions based on the wrong unreliable data.
Every business leader has faced that moment when every decision feels shaky. That’s the quiet and costly ripple effect of unreliable data. In today’s world, where every forecast, customer journey, automation, and executive decision rides on information, data reliability is no longer optional.
Read this blog to understand data reliability, why it matters, and how to create it for your business.
Why causes data to break?
If you’ve ever opened a dashboard and thought, “That number can’t be right,” you’ve witnessed data break in action. It happens quietly, often without warning, and before you know it, entire teams are making decisions on inaccurate or incomplete data.
Here’s what causes your data to break:
- Human error: When teams still rely on manual data handling, even the smallest oversight can happen through pipelines, reports, and business logic. Common examples include something as minor as a missing comma in a CSV file, an incorrect data type in a spreadsheet, or a hastily updated schema
- Schema changes: Data pipelines depend on consistent structure. When a product team adds a new column, renames a field, or changes a format in the source system, it can instantly break downstream processes
- Bad integrations: Modern data stacks pull from multiple sources including CRMs, ad platforms, billing tools, web data analytics, and more. But when integrations aren’t well maintained, data gets lost in translation. APIs fail, connectors time out, and mismatched formats lead to partial or corrupted loads
- Outdated or incomplete data: When datasets aren’t refreshed frequently or fail mid-pipeline, you end up making decisions based on outdated insights
- Data silos: When marketing, product, and finance teams maintain separate versions of truth, inconsistencies are inevitable. This means that when an organization has different systems, metrics, and definitions, it may lead to conflicting reports
- Lack of monitoring and ownership: Many data teams fix issues only after something breaks. But without clear ownership and automated monitoring, problems can linger undetected for weeks. In short, data breaks when no one is accountable for keeping it whole
What is data reliability?
Data reliability is when you can trust your data every single time you use it.
Reliable data stays accurate, consistent, and complete over time, no matter how many systems it travels through or how many people touch it. It’s what separates a one-time “good dashboard” from an organization that makes confident, data-driven decisions every day.
In most cases, you need to define what you mean by 'reliable' in a sufficiently precise way that calculations can be done to compare your notion of reliability.
A reliable dataset is one that was collected with as little bias as possible, that is sampled in a way that is close enough to random. It will depend on the context of what the dataset is (medical, longitudinal, 2 sample, etc) on what the potential sources of bias could be, but that’s the main idea of reliable data.
What are the features of data reliability?
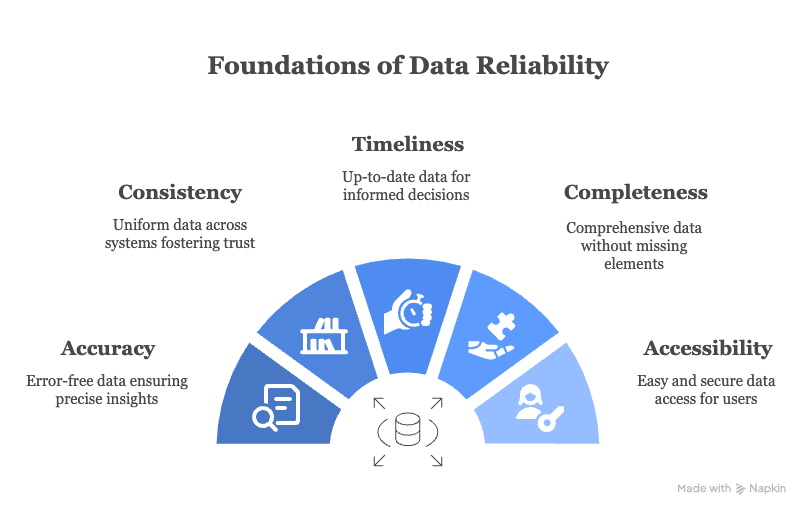
Here’s what reliable data actually looks like in practice:
- Accurate: Reliable data is error-free. If a sales forecast is off by just 3%, that tiny mismatch can distort supply chain planning or revenue projections. Accuracy comes from constant validation, audits, and automated error detection, not one-off cleanups.
- Consistent: Whether a customer’s name appears in your CRM, billing, or support system, it should mean the same thing everywhere. When data conflicts across departments, trust breaks down. Consistency ensures everyone’s reading from the same playbook
- Timely: Even perfect data loses value if it’s stale. Reliable data is updated continuously so leaders make decisions based on today’s facts, not last quarter’s snapshots. Automated pipelines and real-time syncs make this possible
- Complete: Missing data is silent damage as it skews insights without you noticing. A reliable system ensures no missing fields, incomplete records, or gaps in lineage
- Accessible: Reliability also means usability. The right people should have quick, secure access to data without bottlenecks or dependency on IT. Cloud-native architectures make this seamless
Business benefits of data reliability: Why is it important?
Data reliability separates businesses that think they’re data-driven from those that actually are.
Here’s why it matters so much:
- Smarter business decisions: Every strategy, forecast, or investment plan relies on data. But if that data from your business intelligence is unreliable, your decisions would cost your business. Reliable data gives leaders confidence that they’re acting on truth, not assumption. It helps optimize operations, spot risks early, and scale decisions with precision.
- Better AI and machine learning outcomes: AI is only as smart as the data it learns from. Feed your models inconsistent or biased data, and you’ll get distorted predictions for credit scoring, customer churn, or fraud detection. Reliable data ensures your models improves accuracy, reduces bias, and helps your AI deliver insights you can trust
- Staying compliant and audit-ready: In industries like healthcare, finance, or cybersecurity, unreliable data is illegal. Regulations like GDPR and HIPAA demand complete, accurate, and traceable data. A strong reliability framework keeps your organization audit-ready and protects you from hefty fines or reputational damage
- Protecting customer trust: Nothing erodes trust faster than bad data such as wrong invoices, duplicate charges, or emails sent to the wrong person. Reliable data ensures every interaction feels seamless and personalized. When customers see accuracy and consistency, they see professionalism and that builds long-term loyalty
Role of AI and automation in data reliability
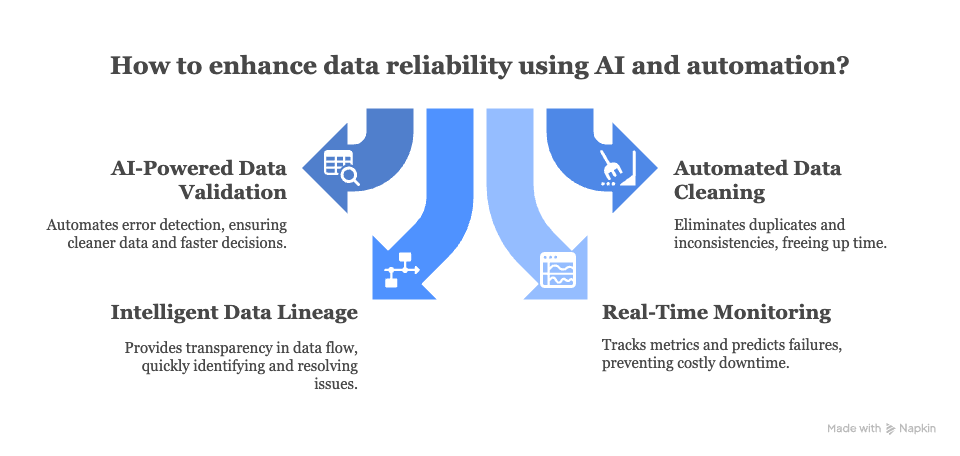
Here’s how AI and automation impacts data reliability for your business:
1. AI-powered data validation
Gone are the days when analysts spent hours hunting for errors in endless spreadsheets. AI-driven validation tools now do that heavy lifting in seconds.
Machine learning models continuously learn what “normal” data looks like and automatically flag anything that deviates such as missing values, outliers, or unexpected patterns. This results in cleaner data, faster decisions, and fewer surprises.
2. Automated data cleaning and standardization
Every data team knows the frustration of dealing with duplicates, inconsistent formats, or outdated entries. AI-powered automation takes these tedious tasks off your plate.
The payoff is less time fixing data and more time finding insights. And when every report pulls from clean, standardized datasets, your organization can finally speak one language of truth.
3. Intelligent data lineage and tracking
In complex data ecosystems, one broken pipeline can ripple across dozens of systems. AI-powered data lineage tools help trace exactly where things go wrong.
It uses machine learning to automatically map how data moves from source to dashboard, giving you full transparency into its flow. With this visibility, teams can quickly identify inconsistencies, pinpoint their origins, and resolve them before they affect decision-making.
4. Real-time monitoring and predictive analytics
The best data teams fix problems and actively prevent them from happening.
Using AI, you can track data reliability metrics in real time, flagging anomalies or latency spikes before they turn into costly downtime. Some even use predictive analytics to forecast potential failures, allowing engineers to act proactively instead of reacting.
Best practices for building reliable data
Data reliability is about ensuring every business decision is rooted in truth. As data volumes grow and systems get more complex, maintaining reliability demands structure, visibility, and discipline.
Here’s how the most data-mature organizations build and sustain reliable data ecosystems.
1. Build a data governance framework that scales
Good data governance is your organization’s rulebook for trust.
A strong framework defines how data is collected, stored, shared, and used across teams. It sets the tone for accountability and ensures compliance with evolving regulations like GDPR or HIPAA.
When roles and responsibilities are clearly defined, data stops being “someone else’s problem” and becomes everyone’s shared responsibility.
2. Use data observability tools to stay ahead of failures
You can’t fix what you can’t see. That’s why modern data teams rely on observability tools to continuously monitor data quality, freshness, and integrity. Observability turns data reliability from a reactive task into a proactive habit. Instead of waiting for the CFO to ask, “Why does this number look off?”, you’ll already know what went wrong, where it happened, and how to fix it.
3. Implement data lineage tracking for full transparency
When something breaks in your data pipeline, you need to trace it fast. That’s where data lineage tracking comes in. AI-driven platforms map the entire journey of your data from source systems to dashboards and give you full visibility into how it’s transformed along the way.
This transparency builds confidence in your analytics and helps teams resolve issues in hours instead of days. It captures every step, so nothing is left to guesswork.
4. Cleanse data regularly
Even the best pipelines can have duplicates, outdated records, and inconsistent formats. Without regular data cleansing, those errors compound quietly and lead to misguided decisions. Automation tools can validate, standardize, and purge irrelevant data on schedule.
Some common data reliability use-cases
When should you start investing in a reliability framework? Which industries feel the pain the most? And which teams should treat this as priority zero? Let’s break it down with real-world examples.
- Financial reporting: If your quarter-end numbers are wrong, nothing else matters. Finance teams can’t afford missing transactions, duplicated entries, or inconsistent definitions of revenue. Reliable data ensures your P&L reflects reality when presenting to the board, and helps you plan your spend optimization and expansion decisions better
- Risk management: Risk teams live or die by the quality of their data. Whether you’re assessing loan defaults, operational breakdowns, or supply chain disruptions, you can’t model risk on shaky foundations. Reliable data helps teams detect early signals, quantify impact, and decide when a risk is worth taking or when it’s time to pull back
- Healthcare: Few industries suffer more from fragmented data than healthcare. Patient records, lab results, insurance systems, pharmacy data, none of it lives in one place. Reliable data ensures diagnoses aren’t based on outdated results, that treatment plans are informed, and that communication errors don’t put patients at risk
- Manufacturing: Production lines run on precision. Bad sensor data can lead to incorrect batch counts, delays, scrap, or missed SLAs. Reliable data keeps the supply chain in sync by forecasting raw materials, maintaining equipment, and predicting defects ahead of time
- Marketing: Marketing leaders need trustworthy data, not massive amounts of unreliable data. Reliable analytics tell you which channels are actually driving revenue, which campaigns are burning budget, and how customers behave across touchpoints. Without reliable data, attribution becomes guesswork and budgets get misallocated
- Research & experimentation: For scientists and research teams, data reliability is the difference between a breakthrough and a false conclusion. Experiments demand consistency, clean inputs, and accurate logs. Unreliable data wastes time, money, and credibility, especially when studies must be audited or replicated
Make your data reliable with 5X
Most data stacks fail because reliability is bolted on instead of architected in.
5X reverses this. It gives data teams a platform where monitoring, lineage mapping, validation checks, schema-change detection, and automated workflows are natively integrated.
Instead of stitching together 12 different tools and hoping nothing breaks, 5X provides a reliability control plane that keeps every dataset trustworthy from ingestion to consumption.
FAQs
What are some data reliability frameworks?
How do you measure data reliability?
How do you ensure data reliability?
Building a data platform doesn’t have to be hectic. Spending over four months and 20% dev time just to set up your data platform is ridiculous. Make 5X your data partner with faster setups, lower upfront costs, and 0% dev time. Let your data engineering team focus on actioning insights, not building infrastructure ;)
Book a free consultationHere are some next steps you can take:
- Want to see it in action? Request a free demo.
- Want more guidance on using Preset via 5X? Explore our Help Docs.
- Ready to consolidate your data pipeline? Chat with us now.
Get notified when a new article is released
Related articles


.png)

How retail leaders unlock hidden profits and 10% margins
Retailers are sitting on untapped profit opportunities—through pricing, inventory, and procurement. Find out how to uncover these hidden gains in our free webinar.
Save your spot










